概述
HBase是一个开源的非关系型分布式数据库(NoSQL),基于谷歌的BigTable建模,是一个高可靠性、高性能、高伸缩的分布式存储系统,使用HBase技术可在廉价PC Server上搭建起大规模结构化存储集群。
HBase最初是以Hadoop子项目的形式进行开发建设,直到2010年5月才正式成为Apache的顶级项目独立发展。伴随着互联网时代数据的澎湃增长,HBase作为基础存储系统得到了快速发展与应用,大批知名商业公司(Facebook、Yahoo、阿里等)不自主地加入到了HBase生态建设队伍,成为Apache最活跃的社区之一。
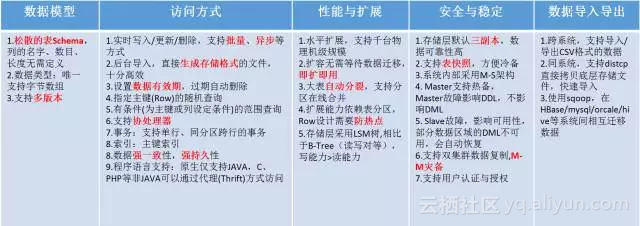
HBase的能力特点,可以简单概括为下表,基于这些能力,其被广泛应用于海量结构化数据在线访问、大数据实时计算、大对象存储等领域。
阿里从2011年初开始步入HBase的发展、建设之路,是国内最早应用、研究、发展、回馈的团队,也诞生了HBase社区在国内的第一位Committer,成为HBase在中国发展的积极布道者。过去的几年时间,阿里累积向社区回馈了上百个Patch, 在诸多核心模块的功能、稳定性、性能作出积极重大的贡献,拥有多位Committer,成为推动HBase的长远发展的重要力量之一。
阿里是一家综合生态型公司,内部庞大业务矩阵高速发展,在基础存储方面,需要更好的功能灵活性、基础设施适应性、服务稳定性、效率成本。
因此,阿里HBase团队发展维护了HBase的内部分支,其基于阿里巴巴/蚂蚁金服的环境和业务需求,对社区HBase进行深度定制与改进,从软件系统、解决方案、稳定护航、发展支撑等全方位提供一站式大数据基础存储服务。
HBase在阿里的使用
Ali-HBase作为阿里巴巴技术大厦的基础存储设施,全面服务于淘宝、天猫、蚂蚁金服、菜鸟、阿里云、高德、优酷等各个领域,满足业务对于大数据分布式存储的基本需求。
在刚刚过去的2016年双11,HBase承载访问量达到了上百GB/秒(写入)与上百GB/秒(读取),相当于全国人民一秒收发一条短信,在业务记录、安全风控、实时计算、日志监控、消息聊天等多个场景发挥重要价值。面对如此规模的业务体量,阿里巴巴团队对于如何基于HBase打造稳定、高效、易用的存储服务,形成了一套完善的产品体系与实践经验,其整体大图如下:
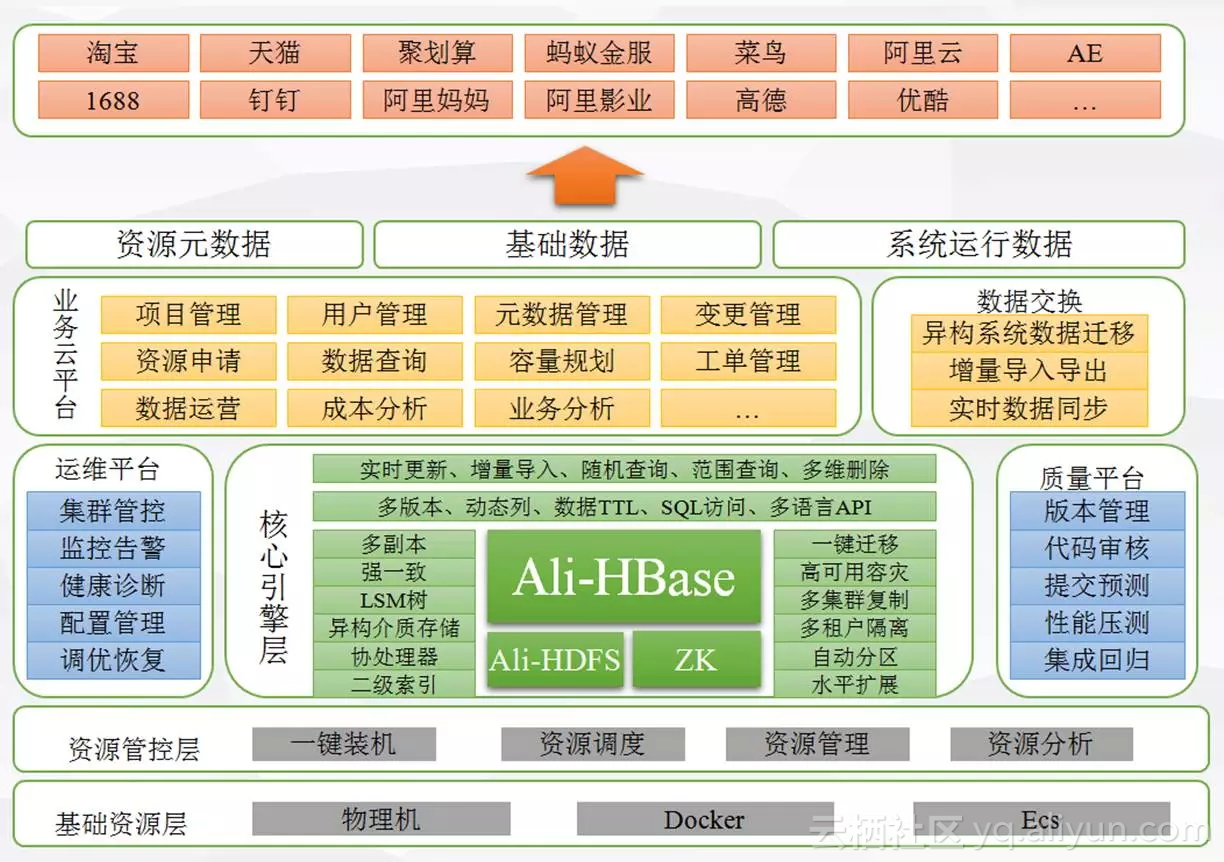
总体上,我们以定制的软件内核为中心,建设质量平台、运维平台、业务平台和数据流设施四大内容,以支持业务对于基础数据服务的全方位需求。
接下来,本文会围绕可用性、数据流、性能优化等方面介绍最近的一些具体工作,希望能够给相关领域的同学带来一点帮助。
高可用建设
服务持续可用是互联网系统的显著特征,但由于物理环境、软件Bug的不确定性,要做到系统的高可用往往不是一件容易的事,尤其是对于有状态的存储系统而言。今天,我们统一使用SLA(服务等级协议)去衡量一个分布式系统的可用性,比如SLA达到99.99%的系统,其全年的不可用时间小于52.6分钟;99.999%的系统,其全年的不可用时间小于5.25分钟,达到这个能力的系统一般可以称之为高可用。
面对断电、断网、硬件故障等物理机房的不可靠性,任何一个高可用系统必须通过双机房,甚至多机房部署的方式进行容灾。对于存储系统,这就要求数据能够在机房间冗余复制,并保证各个机房的数据对上层应用的一致性。所以,高可用建设是我们过去很长时间的重要工作。
集群异步复制
Apache HBase从0.92版本开始支持Replication功能,它会实时地、异步地将一个HBase集群中的增量数据复制(推送方式)到另一个HBase集群,当主集群故障不可用时,应用可以切换访问到备集群,从而实现数据与服务的机房容灾。
下面的篇幅,将主要介绍阿里在使用Replication过程中的经验与改进,期望能和在类似场景工作的同学有所共鸣。
复制效率
由于在线业务的可用性要求,阿里HBase很早便开始使用Replication功能去部署双机房容灾,迎之而来的第一个大问题是数据复制的效率,尤其异地远距离部署(比如上海与深圳跨城复制)时更加严重,表现为数据复制的吞吐小于客户端写入主集群的吞吐,数据不断积压,延迟逐渐增大,只能等待凌晨低峰期逐渐消化。我们对此进行深入分析,着重优化了以下几点,才得以保障跨城集群复制也能稳定保持在秒级内。
- 提升源端发送效率
HBase Replication的基本数据复制过程是源端串行读取HLog的内容,发送到目标端机器,由目标端解析HLog并写入数据写。我们发现,因为源端的串行读取、发送HLog,当集群写入吞吐大的时候,会存在严重的性能瓶颈,为此,我们重构了这一块逻辑,将HLog的读取与发送解耦,并且发送由单线程优化为多线程,使得整体的源端发送能力大幅提升。
- 提升目标端Sink效率
在Replication的默认实现中,源端会按照HLog的原始写入顺序进行回放。为了提升目标端的写入效率,我们将所有待发送的HLog先进行排序,使得同表同Region的数据都能合并处理,同时将目标端的数据写入尽量并行化。
- 热点辅助
尽管做了以上两点后,集群间的数据复制能力大大增强,但是个别服务器仍然会由于负载过大,而产生一定的复制延迟。从本质上来说,这是因为HBase的服务器分配了更多的资源服务于来自客户端的写入请求,当某个服务器成为集群中的写入热点并高负载工作时,这个节点的数据复制基本很难再消化庞大的写吞吐。这是一个曾困扰我们很久的问题,你可以用一些运维的方式去解决。比如开启更多的线程数,但这并不能总有效。因为服务于客户端的线程数,要远远大于Replication的线程数。再比如从热点服务器移走Region,降低吞吐与负载,但热点并不保证是恒定的,可能会跳跃在各个服务器,我们也开发了新的基于历史监控的负载均衡算法,以尽可能地让请求均衡。
很多时候,通过运维管理手段能够控制影响、化解问题,但当你需要维护上百个集群时,一点一滴的运维要求慢慢堆积成很高的壁垒。所以,我们尝试改进系统能力,用自动、一劳永逸地方式去解决热点下的数据复制积压问题。面对热点的基本思路是散列,在这个具体场景上,我们打破原先的自生产自推送的设计,利用整个集群的能力,使得热点服务器上积压的数据(HLog文件),能够由集群中的其他空闲服务器进行消化。
- 配置在线调整
配置的在线调整不仅能极大提升运维幸福感,而且对于系统改进可以产生更加敏捷的反馈。这并不新鲜,但这是一项十分重要的能力,我们在系统改进的道路上也对其特别重视。HBase的Replication功能会有很多参数,我们将其全部优化为可在线调整,给日常的服务支撑带来了很大的价值。
多链路
业务多地多单元部署是阿里技术架构的一项重要特征,这要求基础存储具备数据链路的灵活流动性。今天,阿里HBase会在多地部署多集群,集群间数据相互流动,以满足单元化业务的需求。
在支持数据多链路的生产应用上,我们总结了以下几个要点。
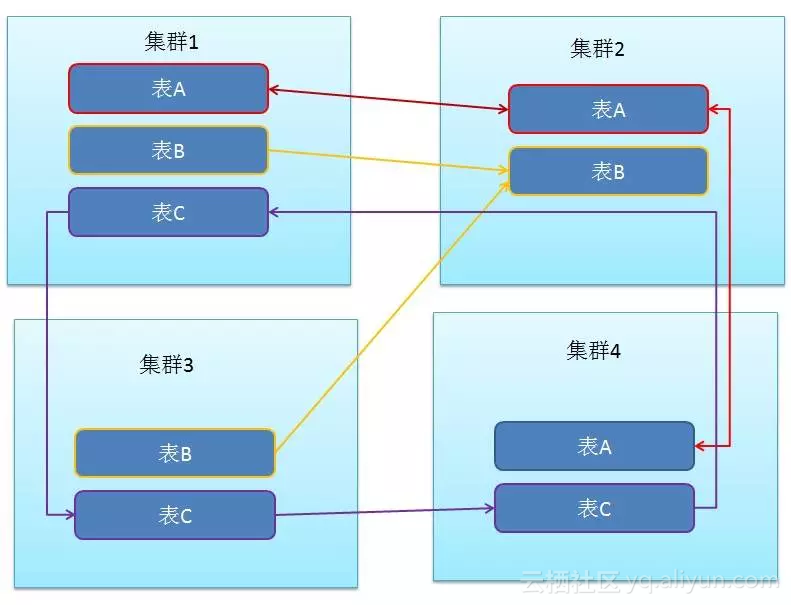
- 表级别链路
当一个HBase集群启用多个数据链路后,我们期望自由设置表的数据可以被复制到其中的一个或多个链路,使得整个数据的流动更加灵活。为此,我们增加了一种特性,通过设置表的属性,以决定该表的数据流向哪些链路,使得整个数据流动图可以由业务架构师任意设计,十分灵活。此外,当需要在集群间热迁移数据时,它也能带来十分重大的作用。 整体效果如下,以表为单位数据可以任意流动:
- 链路可视
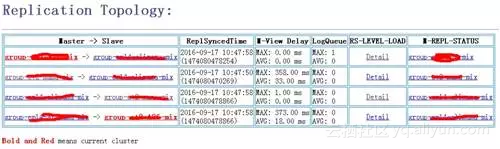
当数据可以在多个集群任意流动后,一个很迫切的需求是链路拓扑以及复制状况的可视。为此,我们强化了Replication的信息层,不仅源端保留它到多个目标的链路信息,而且每个目标端也会保留多个源端到它的链路信息,从而我们可以从任意一个集群绘制整个链路拓扑图。同时,我们极大丰富Replication的运行状况信息,并将之汇聚到HBase的Master节点,由其统一汇总展现,从中我们可以清晰得到数据是否积压、复制的性能瓶颈、节点间的均衡情况、具体的延迟时间等信息,其中复制的延迟时间是一个十分关键的信息。基本信息如图:
- 循环复制
在数据多链路下,会产生一些循环复制的场景。比如集群A->B->C->A,这是一个简单的链接式复制,当数据流过某个集群时,HBase Replication会在数据中添加该集群ID的信息,以防止同一条数据被多次流经同一个集群,基于这个设计,即使复制链路存在环,数据也不会产生无限循环流动。但是,仍然有一个效率问题不得不提,对于A<->B<->C<->A这样一个数据链路,我们发现客户端写入到A集群的数据,在B集群和C集群上会被复制写入两次,一次通过A->B链路写入,另一次通过A->C->B链路写入。所以,为了避免这种写入放大,需要在链路部署上防止产生这种环。在过去实践的一些场景,发现这种环状链路不得不存在,所以系统层面,我们也对Replication做了相关优化,以去除这种写入放大。
- 链路隔离
当源集群配置了多个数据链路后,我们总是期望这些链路之间相互隔离,不会因为一个链路的积压影响其他链路。在大多数时候,这一切都如预期工作,但当集群故障时,糟糕的事情发生了,我们发现一个异常链路会阻塞全部链路的复制恢复,究其原因,是因为在数据复制的恢复期间,很多资源是所有链路共享的。所以,这些资源的链路解耦成为我们的工作,同时,也好好对数据复制的宕机恢复速度进行了优化。
数据的一致性
今天,大多数生产系统会使用异步方式去实现集群间的数据复制,因为这样效率更高、逻辑更清晰。这意味着,集群间数据是最终一致模型,当流量从主切换到备,从备上无法访问完整的数据,因为复制存在滞后,并且当主集群永久不可恢复,数据也会存在部分丢失。
为了满足业务场景的强一致需求,我们采用了两种方式。
第一种,异步复制下的强一致切换。虽然备集群的数据集滞后于主集群,但是在主集群网络健康的情况下,仍然可以保障切换前后数据的强一致。其基本过程如下,首先让主集群禁止数据写入,然后等待主集群的数据全部复制备集群,切换流量到备集群。这里存在两个依赖,一个是集群的写入控制功能(支持禁止来自客户端的数据写入),另一个是复制延迟的确定性,虽然数据是异步复制的,但是我们将数据的复制时间点明确化,即该时间点之前写入的数据已经完全复制到了备集群。
第二种,数据复制使用同步的方式。即当数据写入返回客户端成功后,能保证数据在主备集群均已写入,从而即使主集群完全不可恢复,数据在备集群中也能保证完整。
为了满足类似场景的需求,阿里HBase研发了同步方式的集群间数据复制,具体内容可参考下一节。
冗余与成本
数据在集群间的冗余复制,给系统的可用性带来了数量级的提高,但同时也意味着更大的成本开销,在保证可用性下如何优化成本是一个需要重点思考的问题,阿里HBase在这方面投入了较大精力的尝试,具体内容将在接下来的”性能与成本”章节进行介绍。
集群同步复制
上文提到,HBase集群可以使用异步方式的数据复制来构建双机房容灾,当主集群故障不能提供服务时,就会切换请求到备集群,保障系统整体高可用。然而,异步复制模式下存在的问题是:在服务切换后,由于主备集群间的数据并非强一致,存在部分数据无法通过备集群获取或者访问到的内容过旧。也就是说,如果应用对于数据访问具有强一致要求,现有的异步复制设计,无法在主集群故障时,仍然保证系统的高可用。
为此,阿里HBase团队投入研发集群同步复制功能,使得主集群不可用时,备集群的数据能达到和主集群完全一致,业务可以无感知的切换到备集群。相比于异步复制,同步复制会带来的额外的开销,但整个写入吞吐/性能的影响,在我们的设计中,做到了尽量的相近。其整体功能点如下:
- 数据强一致性保证。数据写入主备集群,主集群不可用后,备集群可以恢复所有在主集群写入成功的数据
- 高性能。主备集群HLog写入采用异步并行的方式写入,对写入性能影响微弱
- 列族级粒度。列族级别的配置,支持同集群下同个表的不同列簇可以使用不同的复制方式,同步或异步。
- 同异步复制共存。任何情况下,同步复制表的任何操作不会影响异步表的读写。
- 灵活切换。备集群不可用,同步复制可以一键切换为异步复制,不阻塞主集群写入。
关于数据的强一致,我们进行了如下定义:
- 返回应用成功,则一定主备都写成功
- 返回应用错误,则未决(主备是否成功不能确定)
- 数据一旦读取成功,则主备永远均可读,不会出现主读成功切换至备后读不到或者备读得到主读不到的情况
- 任何情况下,保证主备集群的最终一致性
我们遵从简单、高效的原则去设计同步复制功能,简单意味着该功能与原核心逻辑保持最大程度的隔离,能够快速达到生产稳定性要求,并能很好地降级成异步复制;高效意味着主备必须并行写,这在错误处理上增加了不少的难度。整体实现方案如下:
- 客户端向主集群写入数据的时候,会并行写入两份Log,一份是本地HLog文件,另一份是备集群的HLog文件,我们称之为RemoteLog.两者皆成功,才返回客户端成功。
- RemoteLog仅在故障切换后,用以回放数据。正常运行时,不做任何使用,备集群的数据仍然通过现有的异步复制链路写入。同时,可以通过停写RemoteLog,把同步复制降级成异步复制。
- HBase数据的多版本特性,使得基于HLog的操作回放具有幕等性,所以,在故障切换后,RemoteLog中的数据回放会存在一定的重复,但不会影响数据正确性。
- 主备集群存在Active和Standby状态,只有Active状态的集群才能接受客户端的数据写入
- 在备集群切换为Active状态之前,会对RemoteLog全局上锁,从而防止客户端写入数据到主集群返回成功。这也意味着,主备集群在任何时刻,只有一个处于Active状态,不会有脑裂发生。
- RemoteLog会定期由主集群清理,主集群服务器的一个HLog文件对应一个或多个RemoteLog,所以当主集群的HLog文件中的数据被完全复制到备集群后,相应的RemoteLog就可以被删除。
其基本结构如图:
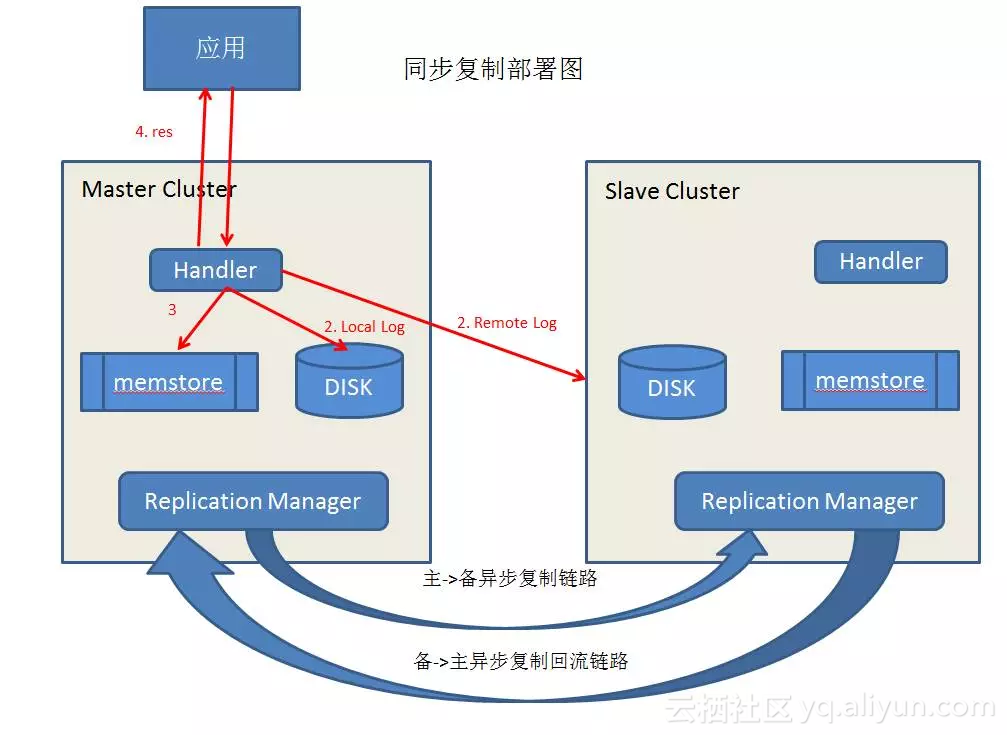
在这里,主备角色是不对等的,我们通过部署进行分配。其中,主->备使用同步复制模式,一旦流量切换到备后,备->主使用异步复制模式。
由于主备双Log的并发写入,使得同步复制的性能能够与异步复制接近,在实际使用中,我们观察到客户端写入响应时间增加小于10%。最后,我们列举一些应用同步复制容灾的场景,以供大家参考。
- 基于状态变更数据的场景。HBase中提供了CheckAndMutate接口,用以支持条件写入/更新/删除,其含义是当某一条件达成时,才执行该写操作。这意味着查询到的数据必须是强一致的,不然就会写入错误的数据。比如,对于一笔交易记录,其状态只能从“已付款”变更为“已发货”,而不能从其他状态变更为“已发货”,所以在数据更新时需要做状态的条件判断。
- 日志/消息的顺序订阅。对于日志/消息产品而言,订阅数据的完整性是其最核心的保证,也就是说通过HBase进行Scan的时候,必须保证能扫描到范围内的每一行数据。如果切换后,主备数据存在不一致,则会出现scan过程中跳过某些数据,造成订阅少数据。
- 流计算。由于流计算不停地基于中间结果和新的数据流进行迭代处理,作为存储中间结果的数据库,必须时刻具备数据的强一致,才能保证数据计算结果的正确性。
总结
集群间的数据复制是HBase用来构建机房容灾、提供高可用性的重要武器,阿里HBase通常使用异步复制方式部署,着重改进其在复制效率、多链路、一致性等方面的能力。同时,也研发了一种高效的同步复制方式,以满足数据强一致场景的容灾需求。
挑战
- GC的挑战
HBase作为JAVA性存储系统,大容量的内存堆使得YoungGC、FullGC的停顿成为我们一直以来挥之不去的痛苦。探究GC的原理机制,我们明确HBase内部的写缓冲Memstore和读缓存BlockCache是造成GC停顿的最大源头,正在尝试用全新研发的完全自管理内存的Map以替换JDK自带的Map,从而消除GC的影响。
- SQL
我们正在尝试提供SQL方式访问HBase。它会增加数据类型,降低用户的开发理解门槛,促进异构系统之间的数据流动效率;它会增加全局二级索引,使得多条件查询更加高效;它会简化查询表达,使得性能优化更加普及;它会增加通用的热点解决方案,帮助用户免去复杂的散列逻辑。
- 容器部署
我们正在尝试将HBase部署运行于Docker之上,使得整体运维更加敏捷,集群伸缩更加自如,资源使用更加充分。